Kapitel 4 Strukturierte Datentypen
Basierend auf den einfachen (atomaren) Datentypen existieren in R die folgenden grundlegenden Datenstrukturen.
| Datenstruktur | Beschreibung |
|---|---|
| vector | Sequenz gleicher Datentypen |
| matrix | Verallg. Vektor in 2 Dimensionen |
| array | Verallg. Vektor mit beliebigen Dimensionen |
| list | Sequenz ungleicher Datentypen |
| data frame | Spezielle Liste mit Vektoren gleicher Länge |
Schema:
| Dimension | Homogen | Heterogen |
|---|---|---|
| 1-Dim. | vector | list |
| 2-Dim. | matrix | data frame |
| k-Dim. | array |
Vektoren und Matrizen sind eine strukturierte Zusammenstellung von Daten gleichen Typs. Ein Vektor kann zum Beispiele eine Reihe von integer Werten bündeln, dann aber keine zusätzlichen logischen Werte oder Zeichenketten aufnehmen. Im Gegensatz dazu erlauben es uns Listen und Data Frames, auch Daten unterschiedlichen Typs zu bündeln. In diesem Kapitel wollen wir uns damit beschäftigen, welche Implikationen die hier skizzierten Eigenschaften der verschiedenen Datenstrukturen für Ihre Anwendung haben.
Damit die Datenstruktur für euch auch visuell an Gestalt gewinnt, folgt eine vereinfachte Darstellung mit den zentralen Eigenschaften der Datenstrukturen. Die Darstellung ist nicht in jeder Hinsicht korrekt, soll aber dazu dienen, die grundlegenden Unterschiede der verschiedenen Datenstrukturen zu veranschaulichen.
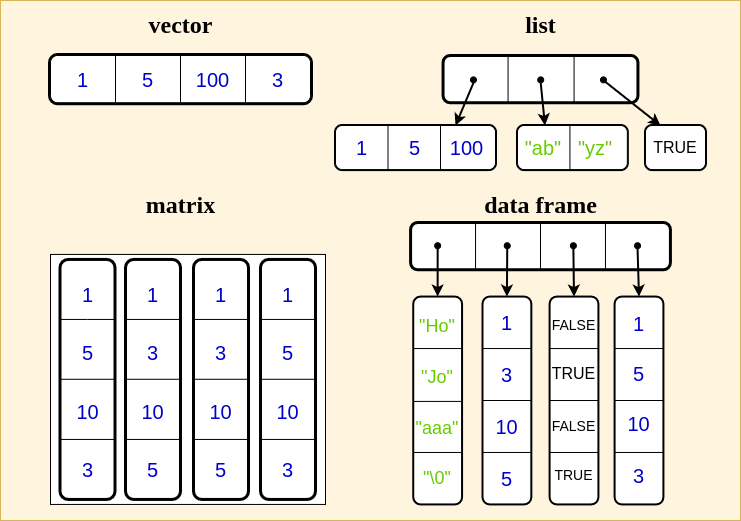
Abb. 4.1: Strukturierte Datentypen
4.1 Vektoren
Vektoren sind sequentiell geordnete Folgen von Werten gleichen Typs. Sie können auf ganz unterschiedliche Art erzeugt werden.
Beispiel: Informationen zum Lineup für die Clubnacht heute. Mit der Funktion c() (kurz für ‘concatenate’ / ‘combine’).
DJ_Alter <- c(34, 38, 28, 25, 20)
DJ_Name <- c("DJ Puma", "Cabanne", "Molly", "Echoton", "cv313")
DJ_Vinyl <- c(FALSE, TRUE ,TRUE ,FALSE , FALSE)
DJ_Alter## [1] 34 38 28 25 20## [1] "DJ Puma" "Cabanne" "Molly" "Echoton" "cv313"## [1] FALSE TRUE TRUE FALSE FALSEAnmerkung: Die DJs gibt es wirklich und es lohnt sich mal reinzuhören :). Das Alter und ob die Personen mit Vinyl auflegen oder nicht, ist allerdings frei erfunden.
Ganz einfach können wir Vektoren auch mit dem Colon-Operator : erzeugen, welcher Zahlenfolgen mit Inkrement 1/-1 generiert.
## [1] 1 2 3 4## [1] 10 9 8 7 6 5 4 3 2 1 0## [1] -1.2 -0.2 0.8 1.8 2.8 3.8 4.8Allgemeinere Folgen können auch mit seq() erzeugt werden:
## [1] 1.0 1.5 2.0 2.5 3.0Auch sehr nützlich:
## [1] "Nein!" "Doch!" "Nein!" "Doch!" "Nein!" "Doch!"4.1.1 Abfragen von Werten durch Subsetting von Vektoren
Mit dem [] Operator können einzelne Elemente eines Vektors abgefragt werden. Hier zum Beispiel die Indexposition 2:
## [1] 38Der Operator ist aber tatsächlich ein “Subset”-Operator und damit wesentlich flexibler und sehr mächtig:
## [1] "DJ Puma" "Molly"## [1] "Cabanne" "Echoton" "cv313"Der Subset-Operator ermöglicht es uns also auch eine Teilmenge des Vektors nach bestimmten Kriterien abzufragen. Hier zum Beispiel die Teilmenge derjenigen Werte, die einen entsprechenden Index haben. Man kann [] als einen Operator verstehen, welcher von
links auf ein Vektorobjekt angewendet wird.
Wird anstelle eines Index ein logischer Vektor (geeigneter Länge) übergeben, so werden alle zugehörigen “wahren” Elemente des Vektors zurückgegeben.
Dies ist tatsächlich eine der häufigsten Verwendungen des Operators (bzw. der Funktion):
## [1] "DJ Puma" "Cabanne" "Molly" "Echoton" "cv313"## [1] FALSE TRUE TRUE FALSE FALSE## [1] "Cabanne" "Molly"4.1.2 Vektorisierte Operationen
Alle atomaren Datentypen sind tatsächlich Vektoren der Länge eins
## [1] 1## [1] 1## [1] 1Dadurch ist es moglich (fast) alle Operationen, welche für atomare Datentypen definiert sind vektorisierte anzuwenden, d.h. elementweise für ganze Vektoren:
## [1] 3 3 6## [1] 2 3 4## [1] 0.0000000 0.6931472 1.0986123## [1] TRUE TRUE TRUE TRUE FALSEDer letzte Ausdruck wertet elementweise aus, ob das jeweilige Alter größer als 21 ist und bildet das Ergebnis in einem logischen Vektor entsprechender Länge ab.
Zur Illustration der folgenden Beispiele benötigen wir noch einen weiteren numerischen Vektor. Da wir nun wissen, wie man vektorisierte Operationen durchführt, können wir leicht einen Vektor mit den ungefähren Geburtsjahren der Personen aus deren Alter berechnen:
## [1] 1988 1984 1994 1997 20024.1.3 Operationen auf Vektoren
Abhängig vom Datentyp eines Vektors existieren verschiedene Funktionen, die einen Vektor als Argument nehmen und diesen auf ein Ergebnis abbilden.
| Operation | Beschreibung |
|---|---|
length() |
Länge eines Vektors |
mean() |
Durchschnittswert eines num. Vektors |
max() |
Maximum eines num. Vektors |
any() |
Ist irgendein Wert eines log. Vektors wahr? |
## [1] 29## [1] TRUE4.2 Faktoren: ein spezieller Datentyp für kategoriale Daten
Die Klasse factor ist in R ein eigener Datentyp, welcher die Typen integer und character derart verbindet, dass man geeignet kategoriale Variablen (nominal/ordinales Messniveau) repräsentieren kann. Dieser Datentyp ist eine Besonderheit von R und ermöglicht es, einfacher kategoriale Variablen statistisch zu untersuchen.
Mit der Funktion factor() können wir einem Vektor die Menge der möglichen Ausprägungen (levels) und deren Bezeichnungen (labels) zuordnen.
x <- factor(x = c(0, 1, 0, 1), # Vektor
levels = c(0, 1, 2), # Mögliche Werte
labels = c("Mann","Frau","Divers")) # Bezeichnungen
x## [1] Mann Frau Mann Frau
## Levels: Mann Frau DiversDie Werte, die in einem Faktor vorkommen können, werden als level bezeichnet und können über die Funktion levels() abgerufen werden. Es spielt hierbei keine Rolle, ob die Werte tatsächlich in dem Vektor auftreten.
## [1] "Mann" "Frau" "Divers"Die Level werden intern mit Integers repräsentiert. Die labels geben Namen für die entsprechenden Levels vor.
## [1] 1 2 1 2Nicht nur character-Vektoren lassen sich in Faktoren umschreiben. Jeder homogene Daten-Vektor kann als Faktor geschrieben werden. Soll dabei auf Labels verzichtet werden, vereinfacht sich das Erstellen:
## [1] 1 2 3 4 5 6
## Levels: 1 2 3 4 5 6Faktoren sind insbesondere hilfreich für deskriptive Statistiken und Abbildungen, da sie es ermöglichen, auch mögliche Ausprägungen eines Merkmals darzustellen, die im Datensatz nicht vorkommen.
Beispielsweise wurde der Wohnort von Studierenden in Leipzig mit den möglichen Antworten Zentrum, Nord, Süd, Ost und West abgefragt. Der character-Vektor z beinhaltet die Antworten einiger Studierender.
## [1] "Nord" "Ost" "Ost" "West" "Süd" "Nord" "Ost"Eine einfache Häufigkeitstabelle zeigt die absoluten Häufigkeiten der Antworten:
## z
## Nord Ost Süd West
## 2 3 1 1Wie wir sehen, hat keine der befragten Studierenden angegeben, im Leipziger Zentrum zu wohnen. Der Wert taucht in der Häufigkeitstabelle also auch nicht auf. Mithilfe eines Faktors können wir nun die Menge aller möglichen Ausprägungen hinterlegen und so auch die Ausprägung mit 0 Antworten sichtbar machen.
## z
## Nord Süd Ost West Zentrum
## 2 1 3 1 0Dies ist auch hinfreich für Abbildungen (siehe Abschnitt 9).
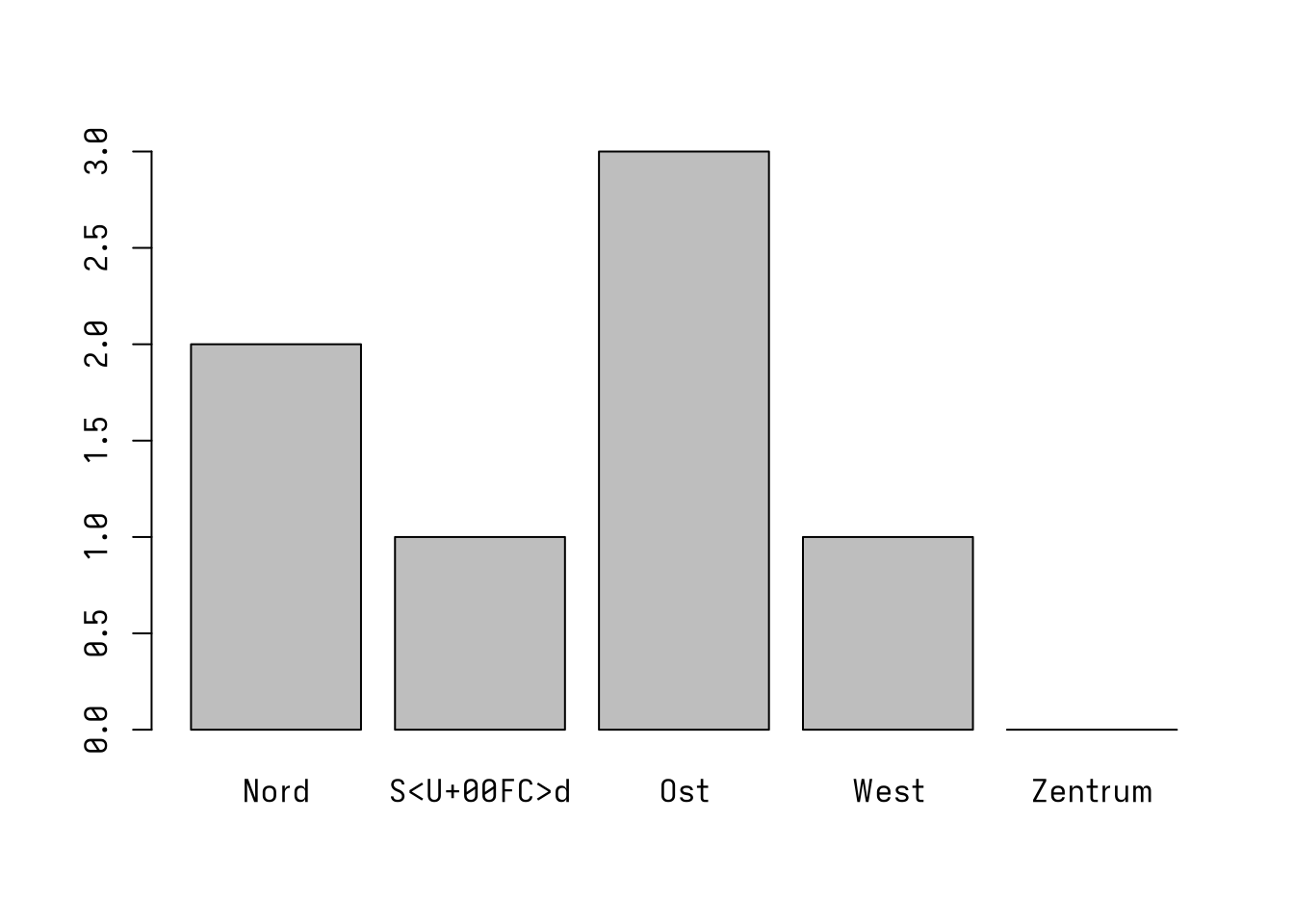
Für die Anordnung der Levels, das Umkodieren oder das Hinzufügen und Löschen einzelner Levels eignet sich das Paket forcats.
4.3 Matrizen
Die Datenstruktur einer Matrix verallgemeinert das Konzept
des Vektors in zwei Dimensionen. Eine Matrix kann z.B. mittels
eines Vektors mit der Funktion matrix() generiert werden:
## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9Die Rückgabe gibt uns schon einen Hinweis darauf, wie wir die Matrix “subsetten” können. In den eckigen Klammern ist jeweils der Index vermerkt, welche Zeile bzw. Spalte dargestellt wird.
Die Indizierung erfolgt dann ähnlich zu Vektoren:
## [1] 2Lassen wir ein Argument offen und geben zum Beispiel nur einen Zeilenindex an, evaluiert der Ausdruck entsprechend zur gesamten angegebenen Zeile.
## [1] 4 5 6Analog kann auch nur das Argument für die Spalte angeben werden:
## [1] 1 4 74.3.1 Benennung von Spalten
Mit der Funktion colnames() lassen sich die Spalten
(columns) einer Matrix benennen/ändern sowie auch abrufen.
## A B C
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9## [1] "A" "B" "C"Gleiches gilt für die Zeilen einer Matrix mit der Funktion rownames().
Über die Spaltennamen kann nun auch auf die Elemente der Matrix zugegriffen werden:
## [1] 2 5 84.3.2 Erzeugung von Matrizen aus Vektoren
Zwei Vektoren können mit der Funktion cbind() in eine Matrix überführt werden.
## DJ_Alter DJ_Geburtsjahr
## [1,] 34 1988
## [2,] 38 1984
## [3,] 28 1994
## [4,] 25 1997
## [5,] 20 2002Analog können mit rbind() zwei Vektoren als Zeilen zu einer Matrix gebunden werden.
Achtung! Achtet darauf, dass die beiden Vektoren den gleichen atomaren Datentyp haben, andernfalls wird der “niedrigwertigere” der beiden zum Typ des “höherwertigen” konvertiert. Bindet man z.B. mit der Funktion cbind() einen Vektor vom Typ character und einen vom Typ logical, so erhält man eine Matrix mit ausschließlich Werten vom Typ character.
4.4 Listen
Eine Liste ist ein “verallgemeinerter Vektor” und lässt als Elemente beliebige Werte oder Datenstrukturen zu:
## $Name
## [1] "Marie"
##
## $Freunde
## [1] "Daphne" "Peer"
##
## $Alter
## [1] 24Die Elemente können gleich einen Namen zugeordnet werden.
4.4.1 Indizierung von Listen
Die Indizierung von Listen funktioniert etwas anders als bei den homogenen Datenstrukturen, da die Liste eigentlich nur Referenzen auf Objekte sammelt. Wenn wir die einzelnen Objekte für Operationen verwenden wollen, nutzen wir am besten den $ (Dollar)-Operator. Mit diesem können die Objekte, auf welche die Liste verweist, direkt “angesprochen” werden.
## [1] "Marie"## [1] "Daphne" "Peer"Die Verwendung des mittlerweile altbekannten Subset-Operators ist ebenfalls möglich. Allerdings muss hier immer die verschachtelte Struktur der Liste berücksichtigt werden, was es deutlich komplizierter macht.
Hier ein Beispiel:
## $Freunde
## [1] "Daphne" "Peer"Mit diesem Aufruf erhalten wir einen Verweis, welcher auf einen Vektor zeigt, welcher die Zeichenketten “Daphne” und “Peer” beinhaltet.
## [1] "Daphne"Diese Funktion bezieht sich im ersten Teil profil_marie[[2]] nun tatsächlich auf den Vektor, auf welchen die Referenz zeigt. Auf diesen wird anschließend nun noch einmal der Subset-Operator für die erste Position angewandt (Unser_Vektor[1]). Auf diese Weise erhalten wir das erste Element des Vektors (was wiederum ein einelementiger Vektor ist).
Deutlich einfacher ist hingegen die Indizierung mithilfe des Dollar-Operators und dem Objektnamen. Der Code wird dadurch wesentlich übersichtlicher:
## [1] "Daphne"Falls ihr noch tiefer in das Subsetting von Listen einsteigen wollt, empfiehlt sich das Kapitel “Subsetting” aus dem Buch Advanced R.
4.5 Data Frames
Die für statistische Zwecke häufigste und wichtigste
Datenstruktur ist die einer Datentabelle, ein sogenanntes dataframe.
Diese kann ganz einfach aus Vektoren erzeugt werden:
## Name Alter
## 1 DJ Puma 34
## 2 Cabanne 38
## 3 Molly 28
## 4 Echoton 25
## 5 cv313 204.5.1 Indizierung von Datentabellen
Das Subsetting funktioniert hier wieder Analog zur Matrix:
## Name Alter
## 3 Molly 28## [1] 34 38 28 25 20Wie bei den Listen ist es aber auch hier möglich, die Spalten über ihren Namen zu selektieren.
## [1] "DJ Puma" "Cabanne" "Molly" "Echoton" "cv313"4.5.2 Aufnahme weiterer Variablen/Spalten
Wie bei den Matrizen auch, können mit der Funktion cbind() Vektoren als Spalten eines bereits bestehenden Data Frames aufgenommen werden.
Wie bei Matrizen können Vektoren mit der Funktion cbind() als Spalten in einen bestehenden Dataframe eingefügt werden.
## Name Alter DJ_Vinyl
## 1 DJ Puma 34 FALSE
## 2 Cabanne 38 TRUE
## 3 Molly 28 TRUE
## 4 Echoton 25 FALSE
## 5 cv313 20 FALSEAlternativ kann eine Spalte ausgewählt werden, die noch nicht existiert, und dann anschließen an einen Vektor gebunden wird. Die Referenz zum Vektorobjekt wird also über den Namen im Dataframe erzeugt.
## Name Alter DJ_Vinyl Geburtsjahr
## 1 DJ Puma 34 FALSE 1988
## 2 Cabanne 38 TRUE 1984
## 3 Molly 28 TRUE 1994
## 4 Echoton 25 FALSE 1997
## 5 cv313 20 FALSE 20024.7 Videos zum Kapitel
Homogene Strukturierte Datentypen (Vektor und Matrix)
Heterogene Strukturierte Datentypen (Liste und Dataframe)
4.8 Literaturverweise
Ergänzend
- R Language Definition Kapitel 2.1 (Nur der Anfang)
Weiterführend
- Advanced R Kapitel 3 und 4
- R-Intro Kapitel 5 & 6 (Speziell auch für hier nicht behandelte Arrays)
- Hands-On Programming with R Kapitel 5