Kapitel 5 Funktionen
Zur Erinnerung:
In R wird grundsätzlich zwischen Funktionen und Objekten unterschieden.
In diesem Kapitel wird es um die Grundlagen im Umgang mit Funktionen gehen.
Technisch gesehen handelt es sich bei R um eine funktionale Programmiersprache. Das heißt, einfach formuliert, dass Problemlösungen durch Funktionen erfolgen.
5.1 Eigenschaften
Die meisten Funktionen in R haben bestimmte Eigenschaften:
1. Funktionen sind “eigenständig”.
Der Output einer Funktion hängt lediglich von seinem Input ab. Wird eine Funktion mit den gleichen argumentativen Werten zweimal ausgeführt, ist der Output in beiden Durchgängen identisch.
Ausnahmen bilden Funktionen, die auf (Pseudo-) Zufallsverfahren beruhen, wie z.B. rnorm().
2. Funktionen helfen beim Erreichen bestimmter Ziele.
Funktionen sollten vom Output her gedacht werden (Welches Ziel soll erreicht werden?). Zur Auswahl einer passenden Funktion muss ein Ziel formuliert werden.
3. Funktionen bestehen im Wesentlichen aus einer Komposition von Base-Funktionen.
In R sind sogenannte primitive Funktionen definiert und bilden die kleinste Einheit von Funktionen.
Beispiel:
## function (x, ...)
## UseMethod("mean")
## <bytecode: 0x564eaa9a53f8>
## <environment: namespace:base>Alle anderen Funktionen bestehen aus einer Komposition dieser primitiven Funktionen.
Beispiel:
## function (x = character(), levels, labels = levels, exclude = NA,
## ordered = is.ordered(x), nmax = NA)
## {
## if (is.null(x))
## x <- character()
## nx <- names(x)
## matchAsChar <- is.object(x) || !(is.character(x) || is.integer(x) ||
## is.logical(x))
## if (missing(levels)) {
## y <- unique(x, nmax = nmax)
## ind <- order(y)
## if (matchAsChar)
## y <- as.character(y)
## levels <- unique(y[ind])
## }
## force(ordered)
## if (matchAsChar)
## x <- as.character(x)
## levels <- levels[is.na(match(levels, exclude))]
## f <- match(x, levels)
## if (!is.null(nx))
## names(f) <- nx
## if (missing(labels)) {
## levels(f) <- as.character(levels)
## }
## else {
## nlab <- length(labels)
## if (nlab == length(levels)) {
## nlevs <- unique(xlevs <- as.character(labels))
## at <- attributes(f)
## at$levels <- nlevs
## f <- match(xlevs, nlevs)[f]
## attributes(f) <- at
## }
## else if (nlab == 1L)
## levels(f) <- paste0(labels, seq_along(levels))
## else stop(gettextf("invalid 'labels'; length %d should be 1 or %d",
## nlab, length(levels)), domain = NA)
## }
## class(f) <- c(if (ordered) "ordered", "factor")
## f
## }
## <bytecode: 0x564eaa580998>
## <environment: namespace:base>5.2 Aufbau
Funktionsaufrufe folgen i.d.R. dem Schema
Funktionsname(Argument 1 = ..., Argument 2 = ..., ...)
Bei den Argumenten handelt es sich meistens…
- um ein oder mehrere Objekte, auf die sich die Funktion bezieht.
- Optionen, die die Verarbeitung des Objekts beeinflussen.
Beispiel:
Die Reihenfolge der Argumente in einer Funktion sind fest definiert.
## [1] 3 3## [1] 2 2 2In diesem Fall wird das erste Argument als Objekt (x) und das zweite als Option (times) erkannt. Die Reihenfolge der Argumente ist aber nur dann relevant, wenn die Argumente nicht benannt werden. Werden die Argumente hingegen benannt, wird die interne Reihenfolge überschrieben:
## [1] 2 2 2## [1] 2 2 2Wichtiger Hinweis!
Es lohnt sich immer, die Argumente in einer Funktion zu benennen. Nicht nur erleichtert es euch, den Code auch nach langer Zeit noch zu verstehen, sondern auch anderen wird das Lesen eures Codes erleichtert.
5.3 Verschachtelungen
Bei dem Output von Funktionen handelt es sich (fast) immer um Objekte. Diese Objekte können natürlich direkt wieder einer Funktion übergeben werden. Diese Eigenschaft ermöglicht es, Funktionen zu schachteln. Hieraus ergibt sich, dass R diese Schachtelungen von Innen nach Außen auflöst.
Im folgenden Beispiel wird also zunächst der Mittelwert des Vektors bestimmt. Im Anschluss wird der Absolutbetrag hiervon genommen, usw.
## [1] 1Dieses Beispiel ist noch relativ gut überschaubar. Im Arbeiten werden diese Ketten jedoch schnell komplexer und unübersichtlich. Eine Alternative hierzu bieten sogenannte Pipes.
5.4 Pipes
Pipes bilden die Alternative zu geschachtelten Funktionen. Erstmals eingeführt wurden diese in der der Package-Familie des Tidyverse (%>%, siehe Kapitel zum Tidyverse). Seit der R Version 4.1.0 ist jedoch auch ein nativer Pipe-Operator verfügbar (|>).
Pipes funktionieren analog zu geschachtelten Funktionen:
- Ein Objekt (X) wird an eine Funktion (z.B.
mean()) übergeben. - Die Funktion gibt ein Objekt zurück.
- Das entstandene Objekt wird an eine weitere Funktion übergeben.
- Auch diese Funktion gibt ein Objekt zurück.
- usw.
Code Beispiel:
## [1] 1An dem Code Beispiel werden die Vorteile von Pipes nochmal deutlich. Die Code-Sequenz kann von oben nach unten gelesen werden (wie eine Geschichte). Außerdem wird deutlicher, was mit den Daten Passiert und der Vorgang kann schnell, Durch das Anpassen von Argumenten abgewandelt werden.
Pro Tipp
Um einen Pipe-Operator einzufügen, kann die Tastenkombination Str + Umschalt + m bzw. CMD + Umschalt + m genutzt werden. Will man statt des nativen Operators den Operator aus dem Tidyverse nutzen, kann das über Tools \(\rightarrow\) Global Options \(\rightarrow\) Code \(\rightarrow\) Use native pipe operator geändert werden.
Video zum Thema Pipes:
5.5 Default Werte
Die meisten Funktionen in R verfügen über sogenannte Default Werte. Hierbei handelt es sich um voreingestellte Werte, die für bestimmte Argumente verwendet werden, wenn bei diesen kein Wert übergeben wird.
Für die Funktion round() ist ein Default Wert von 0 für das Argument digits hinterlegt. Entsprechend sind die folgenden zwei Codezeilen funktional identisch:
## [1] 3## [1] 3In manchen Fällen sind aber auch logische Werte als Default Werte hinterlegt. In der Funktion sd() ist das Argument na.rm enthalten. Enthält der Vektor, der der Funktion übergeben wird ein NA, wird die Funktion auch NA zurückgeben. Schließlich ist ein Wert unbekannt und daher kann auch nicht mit Sicherheit eine Standardabweichung bestimmt werden. Mit dem Argument na.rm können vor der Berechnung alle NA entfernt werden. Hier ist ein logischer Default Wert von FALSE vorgegeben.
## [1] NA## [1] NA## [1] 15.6 Help Fenster
Natürlich muss und soll niemand alle Argumente zu allen Funktionen auswendig lernen. R stellt hierzu bereits intern ein hilfreiches Hilfe-Fenster zur Verfügung.
Für jede Funktion kann dieses über ?Funktionsaufruf aufgerufen werden.
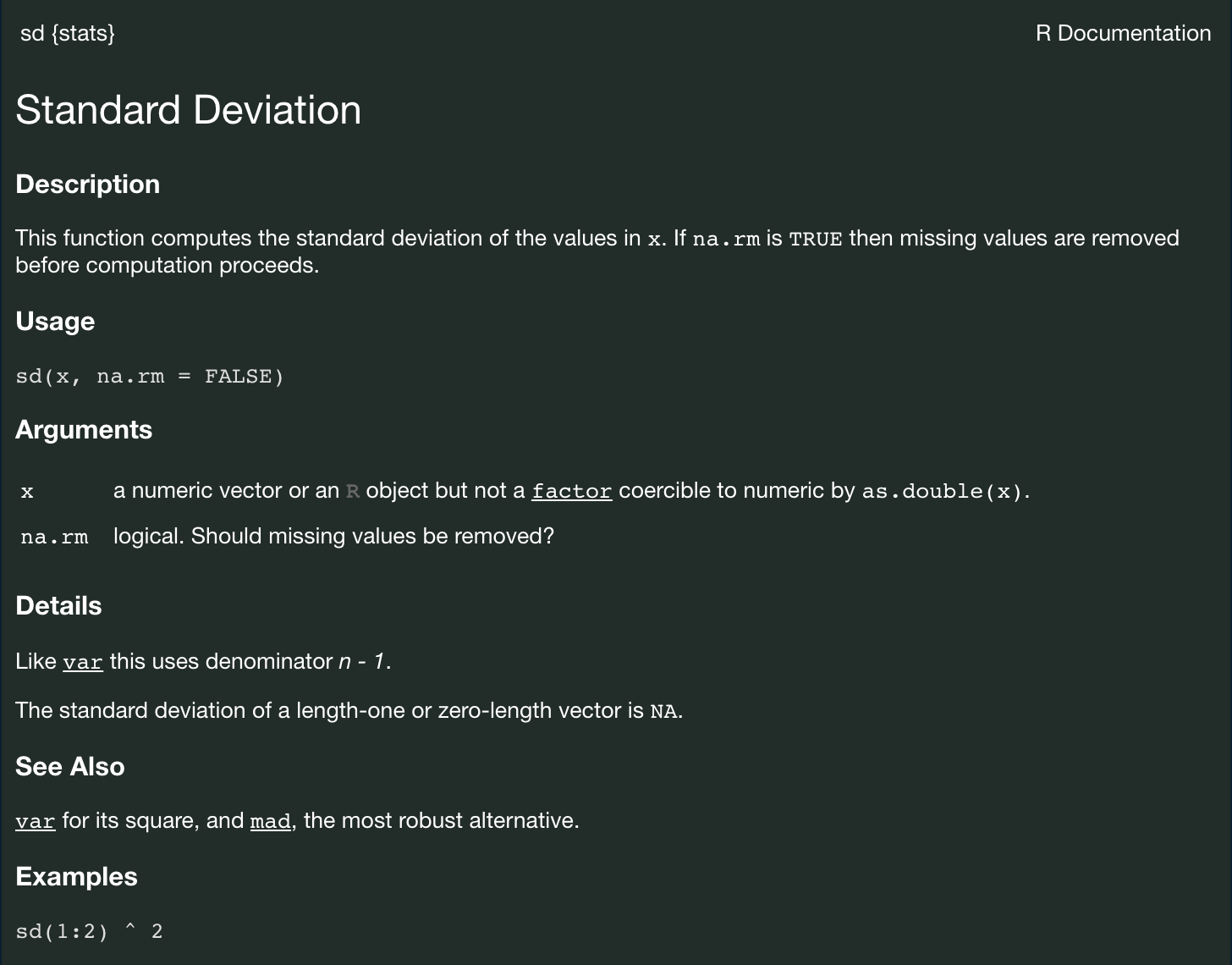
Abb. 5.1: Help Fenster
Die Description gibt detailliert Auskunft über die Funktionsweise der Funktion. Hier ist das “Ziel” der Funktion festgeschrieben, das vor der Auswahl der Funktion von den Nutzer:innen formuliert werden sollte.
Unter Usage sind die verschiedenen Argumente und ihre interne Reihenfolge (siehe Kapitel 5.2) bereits aufgeführt. Die hier aufgeführten Werte für die Argumente sind die hinterlegten Default Werte.
Unter Arguments können die Beschreibungen der einzelnen Argumente gefunden werden. Hier sollte besonders darauf geachtet werden, welcher Datentyp als Wert übergeben werden muss.
Details enthält Hinweise zur internen Berechnung von Werten, Verfahren, etc. Das ist dann besonders relevant, wenn es für die Berechnung von Kennwerten keine einheitlichen Konventionen gibt.
In der Sektion See also sind Verweise zu anderen Funktionen oder Literaturhinweise vermerkt.
Schließlich finden sich im letzten Abschnitt unter Examples konkrete Code Beispiele für die Anwendung der Funktion.
Hinweis!
Je nach Package und Entwickler*in der Funktion ist das korrespondierende Hilfe-Fenster hilfreicher oder weniger hilfreich. Manchmal sind die Beschreibungen sehr kryptisch. Im Zweifel lohnt sich immer eine Google-Suche für euer spezifisches Problem (Stack Overflow!).
Und im Zweifel gilt: Immer mit der Ruhe und keine Panik ;-)
5.8 Literaturverweise
Ergänzend
- R-Intro Kapitel 4
Weiterführend
- towardsdatascience blogpost (Unterschied zwischen Base-R und magrittr Pipe)
- Advanced R Kapitel 6